ねらい: テキストファイルから情報を読み込んで list を生成し,この list をもとに文字列を操作する方法に慣れる.
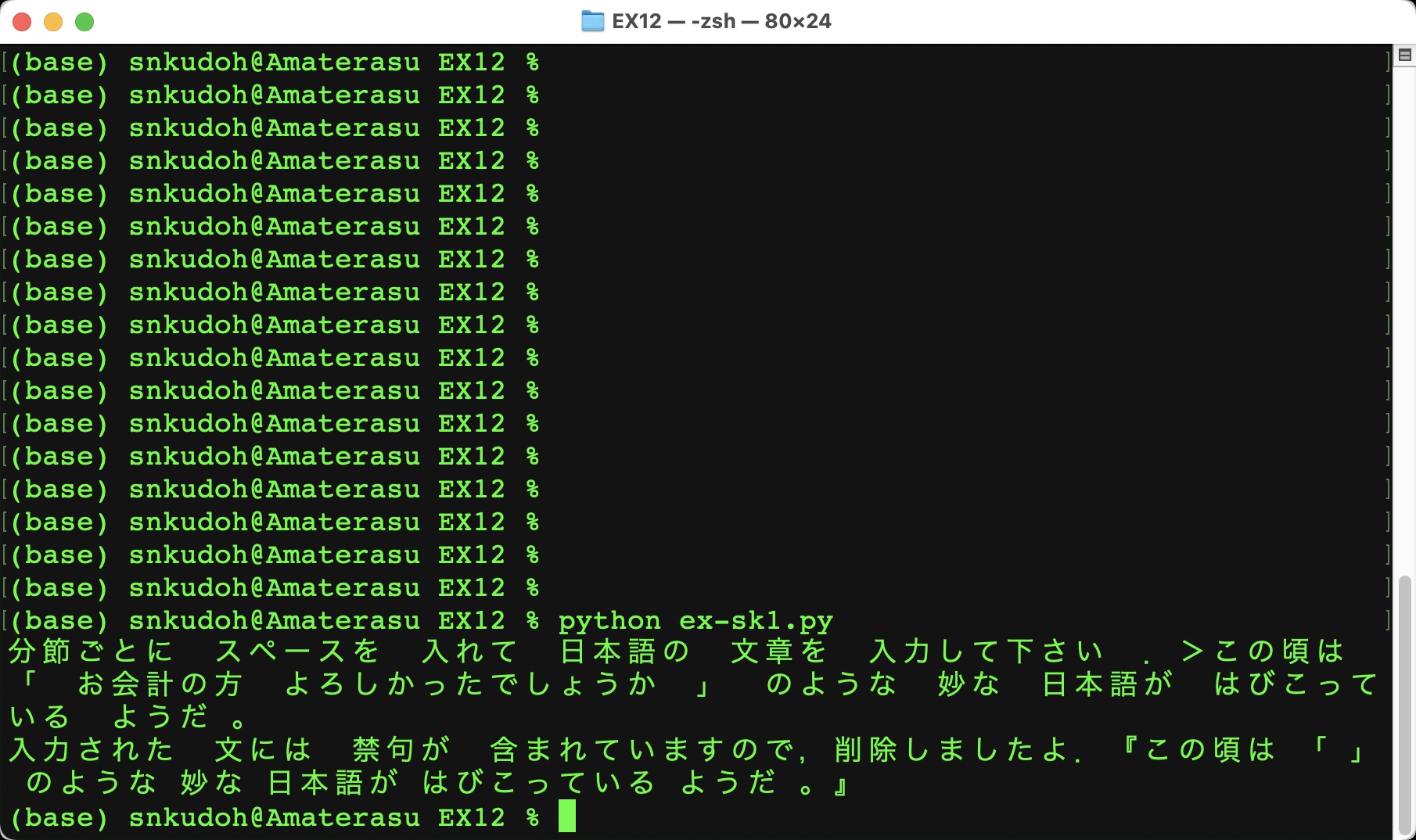
入力された文章から禁句を削除する関数を作成し,実行することを考えよう.
日本語のように区切れがない文章から単語を抽出するのは難しい. 一般的に,自然言語で書かれた文を最小単位の形態素に分割して品詞を推定する処理を形態素解析といい,pythonでも使えるライブラリ,例えば Mecab や Janome がある. 本課題では形態素解析を行う代わりに英語のように単語を半角スペースで区切ることで単語を取り出し,禁句を照合しよう.
例えば以下のような文
この頃は 「 お会計の方 よろしかったでしょうか 」 のような 妙な 日本語が はびこっている ようだ。
を入力すると,禁句リストのファイル kinku.txt (←ここからダウンロードせよ) を照合して,入力文に禁句が見つかればそれを削除した入力文を表示するプログラムを作成しなさい.禁句リストの内容は以下の通り,禁句が半角スペースで区切られて並べられている.改行は入っていない.
なので となっています となっております お疲れ様です よろしかったでしょうか お疲れ お会計の方 グラフを見ると やってみます やってみる がんばります がんばる 努力する すいません
プログラムを起動すると,まず「分節ごとに スペースを 入れて 日本語の 文章を 入力して下さい .>」と表示し,文を入力すると「入力された 文には 禁句が 含まれていますので,削除しましたよ.」のメッセージに続けて禁句を削除した文章を『』で囲って表示するようにしなさい.
ただし,引数に文字列のリスト targettex をとって,禁句を削除した文字列のリストを返す関数 excludecheck(targettex) を作成しなさい.入力した文章をスペースで区切って単語リストを生成し,これを targettex として excludecheck(targettex) を呼び出すようにしなさい.
ヒント1. 要素がリストの中に含まれているかを判定する演算子としては,in 演算子を使うと良い.
ヒント2. 実は
for d in targettex:
if d in exlist:
targetlist.remove(d)
のようにすると想定通りの動作とならない.メソッド remove() は引数で指定した値と等しいリストの要素を検索して最初の要素を削除する.しかし,targettex の要素が exlist に含まれていれば,その targettex の要素が削除されるので繰り返しの中で要素のインデックスがずれる.
ヒント3. 文字列リストから文字列を生成するメソッド join() があるので使うと良い.
ねらい: 各行に一つずつ key と value をカンマで区切って記述した辞書の要素を格納したテキストファイルを読んで,これを辞書に追加する操作に慣れる.
eitango.txt (←ここからダウンロードせよ) の各行に,英単語とその日本語の意味がカンマで区切って1つずつ記述してある.
辞書型の引数 knowledge に eitango.txt から読み込んだ英単語を追加する関数 readknowledge(knowledge) を作成しなさい. 以下の初期の eitango.txt
python,パイソン
prayer,祈り
Japan,日本
Engineering,工学
を読み込むと,辞書の中身は,
knowledge = {'python': 'パイソン', 'prayer': '祈り', 'Japan': '日本', 'Engineering': '工学'}
となる(辞書eitango.txt は学習により,行が追加される).
また,辞書型の引数 knowledge の要素を, eitango.txt の各行に1つずつ key と value をカンマで区切って記録する関数 writeknowledge(knowledge) を作成しなさい.
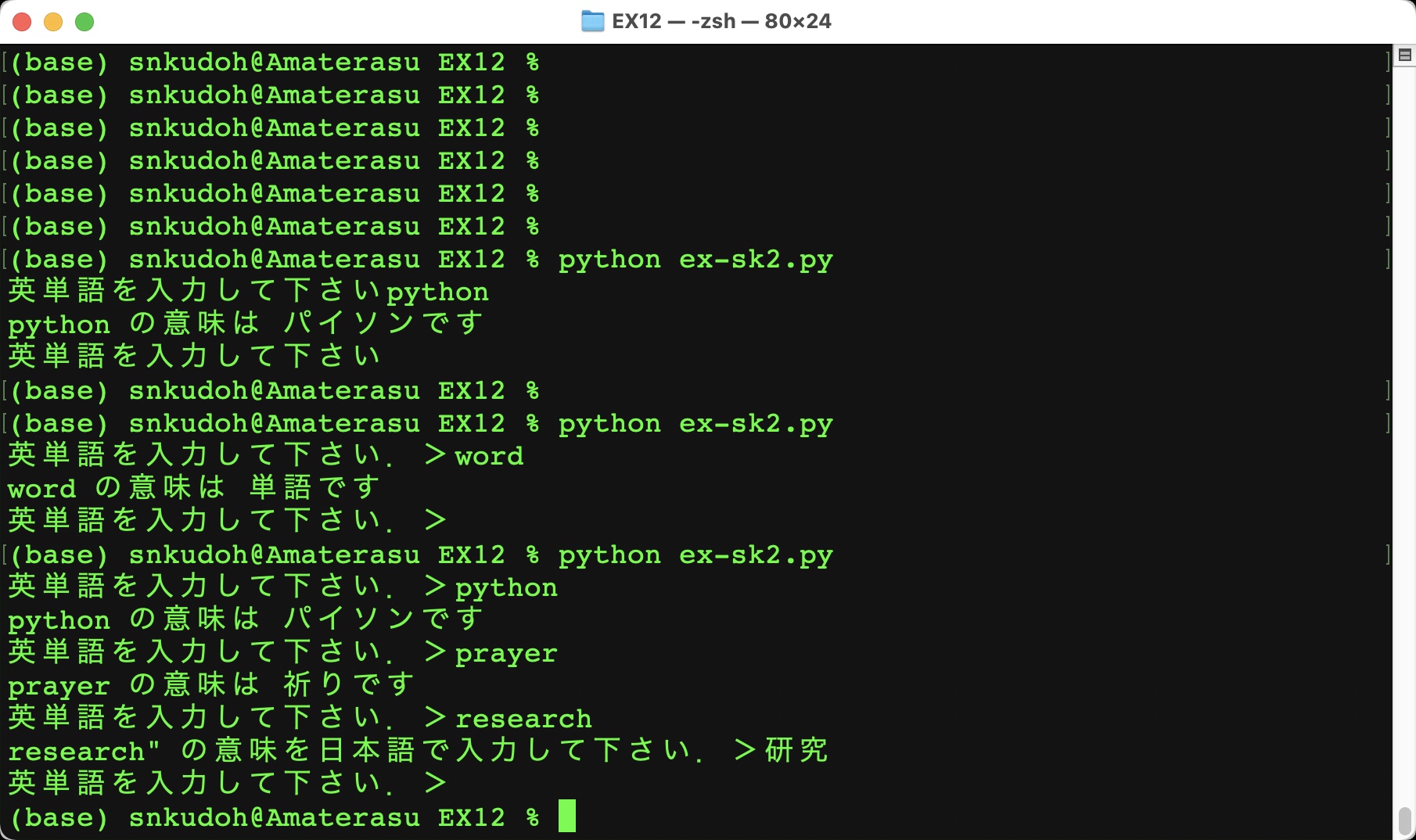
さらに,文字列型の変数 targettex と 辞書型の変数 knowledge を引数にとり,targettex が辞書 knowledge にkeyとして含まれているか検索し,含まれていたら対応するvalueを取り出して,「targettex の意味は value です.」と表示し,含まれていなかったら「"targettex" の意味を日本語で入力して下さい.>」と表示して単語の意味を入力させ,targettex を key,入力された意味を value として辞書型の変数 knowledge に追加する関数 doiknow(targettex, knowledge) を作成しなさい.
上記の3つの関数を用いて,「英単語を入力して下さい.>」とメッセージを表示して単語を入力させ,入力した単語が eitango.txt に登録されていれば,その意味を「○○の意味は××です.」と表示し,登録されていなければ「○○の意味を日本語で入力して下さい.>」とメッセージを表示して単語の意味を入力させ,プログラム終了時に単語とその意味をカンマで区切って eitango.txt に記録する英単語帳プログラムを作成しなさい.
なお,「英単語を入力して下さい.>」で始める処理は繰り返し行うようにし,そのメッセージのあとに何も入力しない,もしくは q を入力するとプログラムを終了するようにしなさい.
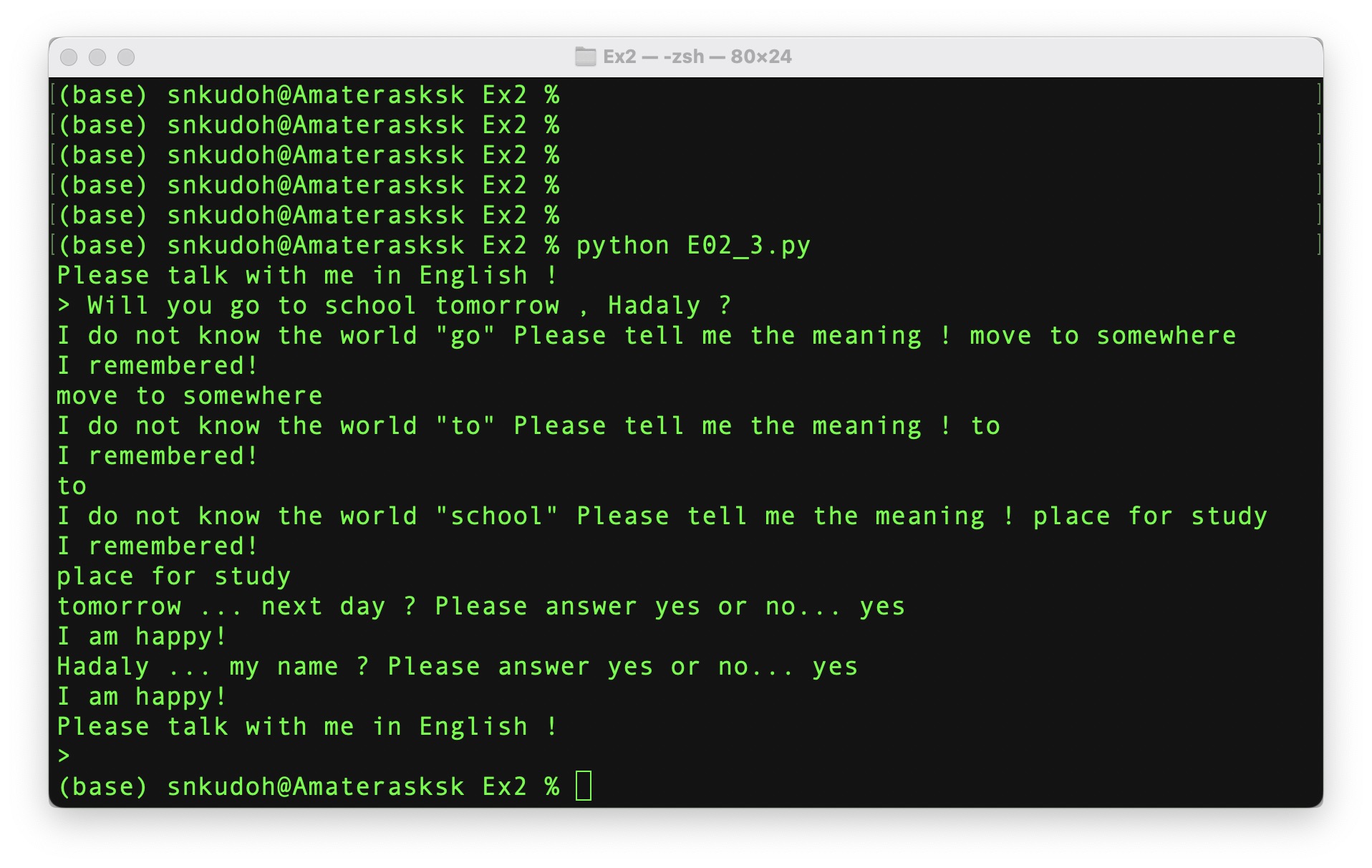
ねらい: 簡易の人工無能プログラムを作成する.
ユーザーの入力に対して,何らかの返答を出力する対話プログラムで,コンピュータに言葉の意味を理解させるのではなく,入力内容に対する応答を学習・蓄積してオウム返しのような返答する簡単なチャットボットを「人工無能」という.
日本語は単語を抽出するのが難しいので,単語をスペースで区切って記述する英語を入力言語とする簡易の人工無能を以下のように作成し,スクリプト E02_3.py を提出しなさい.
起動したら "Please talk with me in English ! (改行)>" と言うメッセージを表示して,英文の入力をさせ,その英文から代名詞など exdic.txt (←ここからダウンロードせよ) に含まれていない単語を取り出してリストを生成し,その全ての要素の単語について,辞書ファイル knowledge.txt (←ここからダウンロードせよ) に登録がない単語があれば "I do not know the word "<単語>". Please tell me the meaning ! " とメッセージを出して意味を英語で入力させなさい. その登録がない単語をkey,単語の意味(英語で記述する)をvalueとして辞書型変数に要素として追加し,さらにこの単語の意味を knowledge.txt に登録するようにしなさい(何も入力がなかった場合は単語の意味は空の要素でかまわない). また,knowledge.txt に登録があった場合は "<単語>...<登録されている意味>? Please answer yes or no... " と確認するようなメッセージを出して,何か入力を促すようにしなさい.このとき,"yes"または"Yes"が入力された場合には "I am happy!" と表示し,それ以外が入力された場合は"Oh, I am sorry..." と表示するようにしなさい. なお,"Please talk with me in English ! (改行)>" で始める処理は繰り返し行うようにし,そのメッセージのあとに何も入力しない,もしくは q を入力するとプログラムを終了するようにしなさい.
ただし,E02_1, E02_2 で作成した関数 excludecheck(targettex), readknowledge(knowledge), writeknowledge(knowledge), doiknow(targettex, knowledge) を修正して利用しなさい(除外する単語のリストは kinku.txt ではなく exdic.txt,単語の意味リストは eitango.txt ではなく knowledge.txt を使用するように修正が必要).
exdic.txt の内容は以下の通り.
what which when who whose why when where how I my me mine myself we our us ours ourselves you your yours yourself he his him himself she her hers herself it its itself they their them theirs themselves this these that those is are was were be been do does did done have has had will would shall should What Which When Who Whose Why When Where How My Me Mine Myself We Our Us Ours Ourselves You Your Yours Yourself He His Him Himself She Her Hers Herself It Its Itself They Their Them Theirs Themselves This These That Those Is Are Was Were Be Been Do Does Did Done Have Has Had Will Would Shall Should ? ! ,
また,knowledge.txt の初期の内容は以下の通り(学習により行は追加されていく).
self,Hadaly
Hadaly,my name
hadaly,my name
ちなみに,"Hadaly"はこの人工無能の名前という設定. Hadalyというのは,フランスの作家ヴィリエ・ド・リラダンによるSF小説『未来のイブ』作中に登場する人造人間の名前である.「アンドロイド」という呼称はこの小説で最初に用いられた.