ねらい: 辞書型の基本的な操作を,繰り返し処理と組み合わせる.
この課題は A07_2 の続きである.手元の課題 A07_2 のソースコードをコピーしてから開始せよ.
課題A07_2のプログラムでは,1回の問い合わせを行うとプログラムが終了していた.連続した問い合わせに対応できるように,プログラムを修正しよう(世の中の各種サーバは,要求を待ち受けて処理をして結果を返す処理を繰り返すことが一般的である).
【繰り返し実行】 課題A07_2で実装された処理,すなわち「登録されている件数の表示,国番号の入力,結果の表示」を,繰り返し実行するようにせよ.また,国番号に0が入力されると終了するようにせよ.
意欲のある人は,教科書5.5節のエラー処理を実装して,空文字列や整数に変換できない文字列の入力でも終了するようにせよ.
復習: 繰り返しには for 文と while 文があるが,本課題の場合は繰り返し対象や回数が指定されていないことを考えて,いずれが適しているか判断せよ.ある条件を満たした場合に繰り返しから抜ける方法についても復習せよ.
【新規登録】 課題A07_2で作成したelse節の処理を改良する.国番号が country_code のキーとして存在していない場合は,続いて国名の入力をうながし,新たな国番号と国名を辞書 country_code に登録して,国番号の入力待ちに戻るようにする.具体的には,「国番号 xx は登録されていません」に続いて,「国名を入力してください」と表示して国名を得て,入力された国名を辞書 country_code に追加せよ.
なおプログラムをテストする際には,country_code に登録されていない国番号と国名の組が必要であるが,https://countrycode.org/ を参照して好みで選択せよ.
【動作確認】 ステップ2.が完成したら,新しく登録した国番号を入力し,適切に登録されていることを確認せよ.
なお,このようにして更新された country_code の内容は,一度プログラムを終了すると失われる. そのため,本プログラムは実用的とは言えない. 再度実行した際にも利用できる実用的なプログラムを作成するには,ファイルやデータベース等に辞書 country_code の内容を保存しておく必要がある. ファイルの読み書きについては,後日学習する.
ねらい: 辞書のキーと値の組に対する処理を行う.
この課題は A07_2 の関連課題である.
課題 A07_2 で使用した,国番号をキーとし,国名を値として格納している辞書 country_code を元に,国名をキーとして国番号を値として格納する辞書 country_name を作成せよ.
次に,作成した辞書 country_name に登録されている項目を,国名順に並べ替え,国名と国番号として表示せよ. ただし,与えられている情報のみで完全に読み方の順序にすることは困難である. これは,日本語文字列のソートはUnicodeによって割り振られている文字コードを基準として行われるためである. 本課題では,カタカナの国名が50音順で並んだ後に,漢字の国名が続けばよく,漢字の国名は読み方の50音順になっている必要はない.
本課題のプログラムの作成にあたっては,以下の知識が必要になると思われる.
辞書型の変数を list() を用いてリスト型にキャストすると,辞書のキーを要素とするリストが得られる.
インタラクティブシェルで挙動を確かめて使用せよ.
>>> d = {3: 'three', 2: 'two', 1: 'one'}
>>> d
{3: 'three', 2: 'two', 1: 'one'}
>>> l = list(d)
>>> l
[3, 2, 1]
>>>
ねらい: プログラムの挙動をソースコードから推測し,適切な動作を行うように修正する.
この課題は A07_5 と同じデータを使用する.
以下のプログラムは,西暦を入力すると,対応する和暦を表示するプログラムである.仕様は以下の通りである.
しかしながら,このプログラムには誤りが数件ある.これらを全て修正し,正しく変換と表示がなされるようにせよ.
import sys
japanese_era = {
'明治': (1868, 1912),
'大正': (1912, 1926),
'昭和': (1926, 1989),
'平成': (1989, 2019),
'令和': (2019, 2025)
}
year = input('西暦 = ')
if year < 1868 and 2025 < year:
print('範囲外です.')
sys.exit() # sys.exit() はプログラムをその時点で終了する
for key in japanese_era:
period = japanese_era(key)
if year == period[0]:
print(f'{key}元年')
elif year < period[1]:
print(f'{key}{year - period[0]}年')
なお,sys.exit() はプログラムをその時点で終了する命令であり,この命令は本実習では初出かもしれないが,誤りではない.
実行例を以下に示す.ただし,以下の入力に対して正しい結果が出されたとしても,全ての誤りが修正できたとは限らないので,十分なテストを実施せよ.
> python b07_3.py
西暦 = 2021
令和3年
> python b07_3.py
西暦 = 1800
範囲外です.
> python b07_3.py
西暦 = 2019
平成31年
令和元年
ねらい: 文章の索引を作る処理を題材として,リストを要素とする辞書を用いて情報の集約を行う.
文章の索引を作る処理を実装する. 通常,書籍の索引では,キーワードが登場するページが示されているが,本課題ではキーワードが登場する文の番号(先頭の文を1とする連番)を提示するものとする.
文章が文に分割され,各文が要素としてタプル text に格納されている. また,索引に掲載する候補となるキーワードが,タプル keywords に格納されている. それぞれは以下のソースコードに示されているため,コピーして自分が作るスクリプトの冒頭にペーストせよ.
text = (
'Pythonは強力で,学びやすいプログラミング言語です.',
'効率的な高レベルデータ構造と,シンプルで効果的なオブジェクト指向プログラミング機構を備えています.',
'Pythonは,洗練された文法・動的なデータ型付け・インタプリタであることなどから,スクリプティングや高速アプリケーション開発に理想的なプログラミング言語となっています.',
'Pythonウェブサイト(https://www.python.org)は,Pythonインタプリタと標準ライブラリのソースコードと,主要プラットフォームごとにコンパイル済みのバイナリファイルを無料で配布しています.',
'また,Pythonウェブサイトには,無料のサードパーティモジュールやプログラム,ツール,ドキュメントなども紹介しています.',
'Pythonインタプリタは,簡単にC/C++言語などで実装された関数やデータ型を組み込み,拡張できます.また,アプリケーションのカスタマイズを行う,拡張言語としても適しています.',
'標準オブジェクトやモジュールの詳細は,「Python標準ライブラリ」を参照してください.',
'また,正式な言語定義は,「Python言語リファレンス」にあります.',
'C/C++言語で拡張モジュールを書くなら,「Pythonインタプリタの拡張と埋め込み」や「Python/C APIリファレンスマニュアル」を参照してください.',
'Pythonの解説書も販売されています.'
)
keywords = (
'Python', 'プログラミング言語', 'データ', 'オブジェクト指向', 'ライブラリ', 'バイナリファイル', 'ウェブサイト', 'C/C++', 'インタプリタ', 'Java'
)
キーとして各キーワード,値としてそのキーワードが登場する文番号のリストを持つ辞書 lines_appeared を構築せよ. 次に,辞書 lines_appeared に基づき,キーワードをソートして,英語(アルファベット順)→日本語(五十音順)に,各キーワードが登場する文番号を表示せよ.
以下に出力の先頭部を示す.
C/C++: 6 9
Python: 1 3 4 5 6 7 8 9 10
インタプリタ: 3 4 6 9
ねらい: 実用的な処理の例として,ハフマン符号のエンコードとデコードを行う.
ハフマン符号化 Huffman coding とは,出現頻度に応じて異なる長さの符号を割り当てる符号化方式である. 出現頻度の高い記号に短い符号を割り当てることによって,可逆的なデータ量の圧縮を実現する. 符号化された記号列に,前から順番にあてはまる符号を探すと,必ず一意に復号する(平文に直す)ことができるようになっている. ハフマン符号の詳細についてはこれ以上説明しないので,情報理論の教科書等で各自確認すること.
英語のアルファベットおよび空白の出現頻度について調査した結果から,以下の符号表が作成されているとする.
huffman_table = {
' ': '111',
'E': '010',
'T': '1101',
'A': '1011',
'O': '1001',
'I': '1000',
'N': '0111',
'S': '0011',
'H': '0010',
'R': '0001',
'L': '10101',
'D': '01101',
'C': '00001',
'U': '00000',
'F': '110011',
'M': '110010',
'W': '110001',
'Y': '101001',
'P': '101000',
'G': '011001',
'B': '011000',
'V': '1100000',
'K': '11000011',
'X': '110000100',
'J': '1100001011',
'Q': '11000010101',
'Z': '11000010100'
}
この割り当て表を用いて,以下の文を暗号化せよ.
MASTERY FOR SERVICE
また,以下の暗号文を平文に直せ.
11010010010111110000101010000010000000111000011111011000000110011100010111111110011100111000010011111000010110000011001010100000111111001110000001000011111101001001011110101101111000010100101001111011011001011001
プログラムは2つの処理を順次行い,それぞれの結果を出力するようにせよ.
ねらい: 実用的な処理の例として,クラスタリング法の一つである k-means 法を試す.
2次元空間に30個の点が分布しており,点の座標が以下のようにタプルのリストとして与えられている.
points = [
(-13.47, -7.34),
(-56.96, 15.23),
( 0.60, -9.54),
( -3.89, -32.66),
( 55.13, 56.38),
(-54.38, 14.64),
(-29.27, 19.41),
( 51.16, 71.48),
(-33.81, 29.09),
(-71.64, 36.63),
( 46.44, 41.29),
(-58.29, 42.10),
(-61.56, 37.31),
( 63.89, 46.12),
( 35.35, 50.41),
( 14.12, -24.65),
( 25.28, -6.46),
(-30.62, 18.80),
( 34.29, 57.90),
( 11.21, -29.62),
( 76.77, 42.67),
( 52.89, 27.45),
( 58.86, 75.85),
(-46.89, 28.98),
( 41.97, 79.74),
( -1.56, 1.17),
( 4.99, -12.85),
(-74.88, 35.72),
( 15.32, -14.80),
( 17.34, -8.07)
]
これを3つのクラスタに分類したい.クラスタの番号を0,1,2とする.
以下の手順に従って,各点がどのクラスタに属しているかを決定せよ.
結果は,クラスタ0,1,2の順に,各クラスタに属している点を以下のフォーマットで出力せよ.
クラスタ番号: (点のx座標, 点のy座標) クラスタ0,1,2の中心との距離
先頭はクラスタ番号であるが,本手法ではクラスタ番号が何番になるかは固定できないため,0番のクラスタに属している点が異なる可能性がある.
0: (-56.96, 15.23) 13.57 70.52 115.66
0: (-54.38, 14.64) 13.40 67.93 113.45
0: (-29.27, 19.41) 24.07 49.64 88.40
:
2: ( 58.86, 75.85) 120.67 104.16 22.12
2: ( 41.97, 79.74) 107.22 100.50 26.64
なお,出力結果が妥当かどうかは,2次元平面上へのプロットを行えば判断できる. Python ではグラフ描画のためのモジュールとして Matplotlib が広く使用されている. Matplotlib の使用方法に関する情報は豊富にあるため,試してみよ. 出力例を以下に示す.
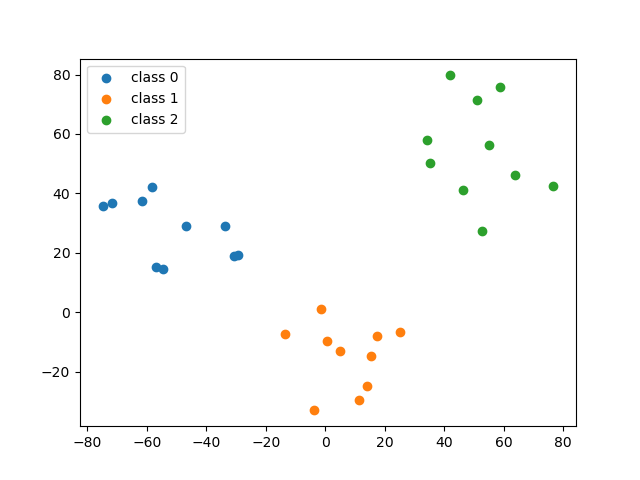
あるいは,出力された結果を元に,別途グラフを描画するアプリケーションで描画してもよい.